
As EU AI Act enforcement gets closer, Article 10 is where a lot of high-risk AI programmes will either stand up—or fall apart. Teams often spend months on classification, transparency language, and “what the fines could be.” But when regulators show up, they’ll start with something more concrete: can you prove your datasets were governed properly? Under Article 10, weak data governance isn’t an engineering inconvenience anymore. It’s compliance risk.
Related reading:
Understanding Article 10 dataset governance requires more than documentation. Regulators increasingly expect operational evidence that demonstrates how data was sourced, evaluated, and monitored in practice.
Read the full analysis here:
EU AI Act Compliance Is Not Documentation — It Is Operational Evidence
With high-risk obligations expected to apply broadly from August 2, 2026, Article 10 is no longer something you “circle back to.” If your high-risk system learns from data, you’ll be expected to show auditable controls for training, validation, and testing datasets—where the data came from, what changed during preparation, how bias was checked and handled, and whether the data actually matches the deployment context.1
For compliance, legal, and data leaders, the shift is the standard of proof. “We reviewed the data” won’t carry much weight. What matters is the trail: sourcing records, preparation steps, quality checks, bias analysis, what was fixed, what was accepted, and why. Article 10 turns data governance into something you may need to defend line-by-line during an audit.
The stakes are high. Non-compliance with data governance duties for high-risk AI can expose organizations to fines of up to 4% of global annual turnover and, in some cases, corrective actions that disrupt operations—pausing deployments, requiring retraining, or forcing systems off the market until issues are fixed.2 And when enforcement happens, the root cause is often boring but expensive: unclear provenance, weak documentation, or datasets that don’t match the real world the model is being used in.
What’s changing in practice is that outcomes alone are no longer the whole story. Regulators will increasingly look at the process behind the outcome: what you measured, what you monitored, and what evidence you can produce. If data governance still lives in scattered spreadsheets and informal team habits, it becomes hard to demonstrate control when scrutiny arrives.
This guide is for people who have to make Article 10 operational—before enforcement pressure forces rushed work. We’ll go through the text, explain what each paragraph requires in plain language, and translate it into controls that are actually buildable: dataset inventory, provenance records, preparation governance, quality and representativeness tests, bias workflows, lineage, and audit-ready documentation. You’ll also get a practical implementation roadmap aligned to the August 2026 deadline.
Whether you sit in compliance, legal, data, or ML engineering, Article 10 is one of the provisions you can’t afford to “kind of” comply with. If your organisation is building or deploying high-risk AI, strong data governance is the backbone of everything else—documentation, monitoring, conformity assessments, and defensible decisions. Doing it early keeps you in control. Doing it late is usually more expensive.
Note on scope: While this guide focuses on operationalizing Article 10 (data governance, lineage, and bias controls), it is important to remember that Article 10 sits within a broader high-risk compliance framework. Articles 8 and 9 establish the overarching compliance principles and risk management obligations that shape how Article 10 should be implemented in practice.
Update note: This guide stays focused on operationalizing Article 10, but we’ve added the overview below to show how Article 10 connects to Articles 8 and 9, based on community feedback.
0. How Articles 8, 9, and 10 Work Together (The High-Risk Compliance Stack)
This guide focuses on Article 10 because it is where many high-risk AI compliance programmes succeed or fail in practice:
you either have auditable controls over your datasets — or you don’t. But Article 10 is not meant to operate on its own.
In the EU AI Act’s high-risk framework, three provisions work as a connected stack:
- Article 8 sets the overarching compliance lens — your system must align with its intended purpose and reflect the generally acknowledged state of the art.
- Article 9 requires a continuous risk management system across the AI lifecycle — identifying, evaluating, mitigating, and monitoring risks to health, safety, and fundamental rights.
- Article 10 provides the data governance evidence — provenance, preparation records, quality and representativeness tests, bias workflows, gap logs, and traceability.
The operational point is simple: Article 10 generates evidence that should feed into Article 9.
Bias findings, dataset limitations, representativeness gaps, and mitigation decisions should not remain informal engineering notes.
They should be logged, tracked, reviewed, and re-tested as part of the risk management process.
At the same time, Article 8 influences how you justify your Article 10 controls.
When you choose quality thresholds, fairness metrics, bias mitigation methods, or lineage tooling, you should be able to explain
why those choices are appropriate for the system’s intended purpose and why they reflect a state-of-the-art approach for that context.
A credible answer is: “Here is our Article 9 risk record, and here is the Article 10 dataset evidence that supports it —
including what we tested, what we found, what we changed, and what residual risks we accepted and why.”
A simple mapping teams can actually use
| Operational activity | Article 10 produces | Article 9 uses | Article 8 expects |
|---|---|---|---|
| Bias testing and mitigation | Bias results, mitigation actions, residual-risk notes | Risk register entries, mitigation tracking, review cadence | Justification that methods reflect the generally acknowledged state of the art for the intended purpose |
| Quality and representativeness thresholds | Metrics, sampling results, acceptance criteria | Risk acceptance decisions, monitoring triggers when drift appears | Clear justification for thresholds and tools (“why this is reasonable now”) |
| Lineage and provenance | Traceability from source → preparation → training → deployment | Incident reconstruction, post-market monitoring evidence | Governance architecture aligned with intended purpose and accountability |
These connections ensure Article 10 is not treated in isolation. Dataset gaps, bias findings, or lineage issues identified under Article 10 should become traceable risk entries within the Article 9 risk management system, with decisions justified under Article 8’s intended-purpose and state-of-the-art principles.
1. Full Text of Article 10 — Data and Data Governance (EU AI Act)
Before interpreting Article 10, it is essential to read the provision as regulators will apply it. What follows is the official wording of Article 10 of the EU Artificial Intelligence Act, reproduced in full from the EU’s legal text repository. This text forms the legal baseline against which high-risk AI systems will be assessed once enforcement begins.3
Article 10 — Data and Data Governance
1. High-risk AI systems which make use of techniques involving the training of models with data shall be developed on the basis of training, validation and testing data sets that meet the quality criteria referred to in paragraphs 2 to 5.
2. Training, validation and testing data sets shall be subject to appropriate data governance and management practices. Those practices shall concern in particular:
- (a) the relevant design choices;
- (b) data collection, including the origin of the data and the purpose of the data processing;
- (c) data preparation processing operations, such as annotation, labelling, cleaning, enrichment and aggregation;
- (d) the formulation of relevant assumptions, notably with respect to the information that the data are supposed to measure and represent;
- (e) an assessment of the availability, quantity and suitability of the data sets;
- (f) examination in view of possible biases;
- (g) appropriate measures to detect, prevent and mitigate possible biases;
- (h) identification of relevant data gaps or shortcomings.
3. Training, validation and testing data sets shall be relevant, sufficiently representative, free of errors and complete, in view of the intended purpose of the AI system. They shall have the appropriate statistical properties, including, where applicable, as regards the persons or groups of persons in relation to whom the high-risk AI system is intended to be used.
4. Training, validation and testing data sets shall take into account, to the extent required by the intended purpose, the characteristics or elements that are particular to the specific geographical, behavioural or functional setting within which the high-risk AI system is intended to be used.
5. To the extent that it is strictly necessary for the purposes of ensuring bias detection and correction in relation to the high-risk AI systems, the processing of special categories of personal data referred to in Article 9(1) of Regulation (EU) 2016/679 shall be permitted, subject to appropriate safeguards for the fundamental rights and freedoms of natural persons. Such safeguards shall include technical limitations on the re-use of such data, state-of-the-art security and privacy-preserving measures, including pseudonymisation, and measures to ensure that such data are deleted once the bias has been corrected or where the data are no longer strictly necessary.
6. Paragraphs 1 to 5 shall not apply to high-risk AI systems that do not use techniques involving the training of models with data. In such cases, paragraph 3 shall apply only to testing data sets.
This provision is aimed primarily at providers of high-risk AI systems. In practice, it also shapes what deployers will need to rely on during audits, investigations, and post-market monitoring—because the evidence has to exist somewhere, and regulators will ask for it.
2. Article 10 Decoded: Paragraph-by-Paragraph Breakdown With Practical Meaning
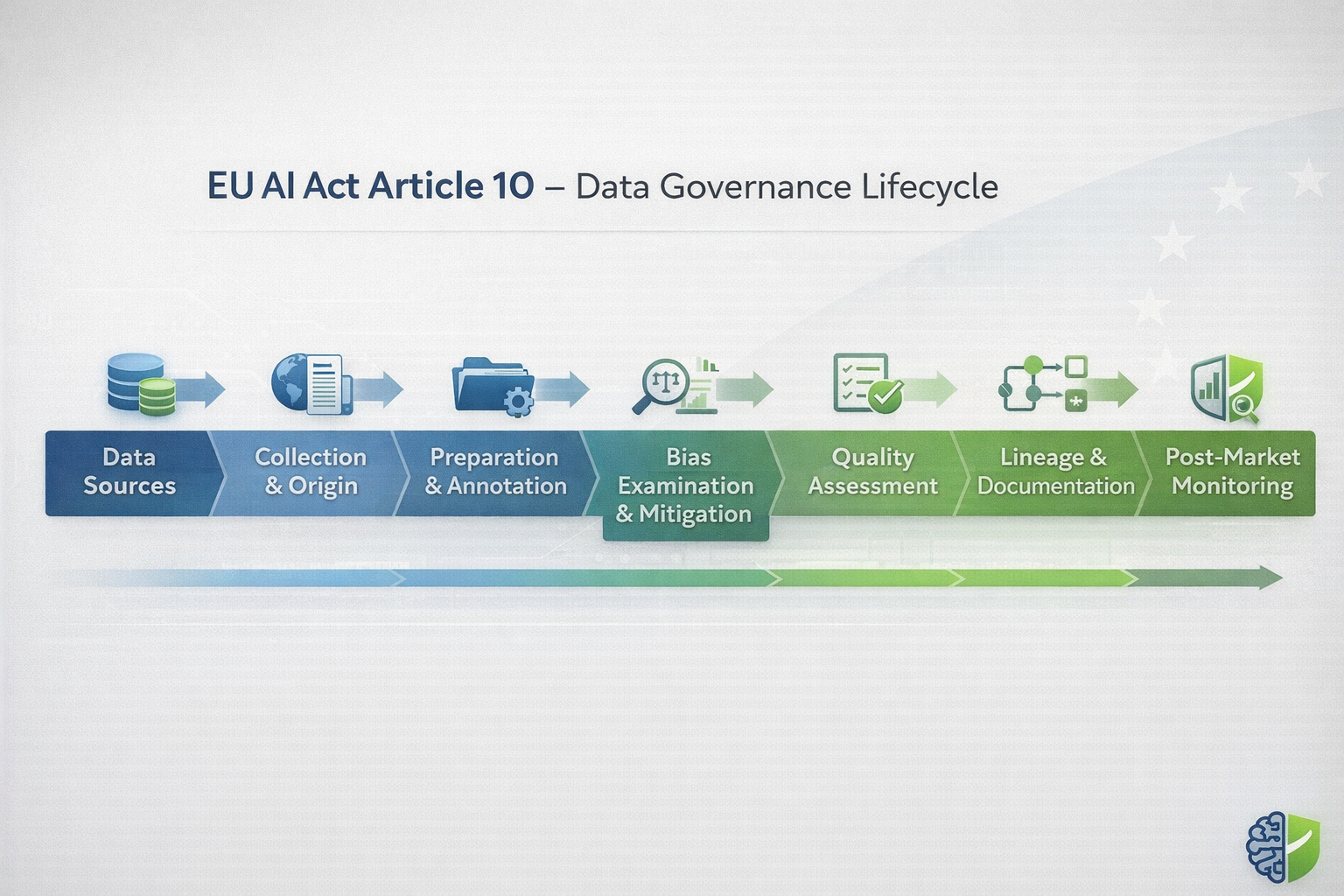
Article 10 is often reduced to “use good data.” That’s not wrong—it’s just not enough. The real requirement is provable, auditable data governance. In other words: if someone challenges your system, you should be able to show how data risks were identified, tested, and managed across the dataset lifecycle—not just say they were.
Article 10(1): Scope — When Article 10 Applies
Paragraph 1 defines the scope of Article 10. It applies to all high-risk AI systems that use techniques involving the training of models with data. In practice, this includes the vast majority of modern machine learning systems used in employment, credit scoring, biometric identification, healthcare, education, and access to essential services.
Where model training is involved, three datasets fall under scrutiny: training, validation, and testing. Each must meet the quality and governance requirements set out in the following paragraphs. This means organizations cannot focus solely on training data while treating validation and testing datasets as secondary or informal.
From a compliance perspective, this paragraph establishes a simple rule: if your high-risk system learns from data, Article 10 applies in full.
Article 10(2): Mandatory Data Governance Practices
Paragraph 2 is the operational heart of Article 10. It does not merely require outcomes; it mandates specific governance practices. Regulators will expect documented processes covering each of the elements listed from (a) to (h).
(a) Relevant design choices
Organizations must be able to explain why certain data sources, features, or preprocessing methods were chosen. This includes trade-offs made between accuracy, fairness, explainability, and feasibility. Design decisions that affect downstream risk must be intentional and documented.
(b) Data collection and origin
You must know where your data came from, why it was collected, and under what legal basis it is processed. Shadow datasets, scraped data of unclear provenance, or inherited legacy datasets present immediate compliance risk in 2026.
(c) Data preparation operations
Annotation, labeling, cleaning, enrichment, and aggregation are not neutral steps. Each introduces assumptions and potential bias. Article 10 requires these steps to be governed, not improvised, with clear documentation of methodologies and quality controls.
(d) Assumptions about what the data represents
This is one of the most overlooked obligations. Providers must articulate what the data is intended to measure and, just as importantly, what it does not measure. Unexamined assumptions often become the root cause of discriminatory outcomes.
(e) Availability, quantity, and suitability
It is not enough to have “a lot of data.” Regulators will assess whether the dataset is suitable for the system’s intended purpose. Sparse, outdated, or context-mismatched data can invalidate compliance claims even if models perform well technically.
(f) Examination for possible biases
Bias examination is mandatory, not optional. This includes risks to fundamental rights, discriminatory impacts, and safety concerns. The absence of documented bias analysis is likely to be interpreted as non-compliance.
Operationally: treat every documented bias finding as a risk item that should be recorded and tracked through your Article 9 risk management system, with clear ownership, mitigation actions, and review dates.
(g) Bias detection, prevention, and mitigation measures
Identifying bias without acting on it is insufficient. Article 10 explicitly requires mitigation measures. These may include re-sampling, feature review, model constraints, or post-processing corrections.
Operationally: mitigation should produce evidence — what you changed, what improved, what remains, and how you will monitor it post-deployment — because that is what makes the risk management process defensible.
(h) Identification of data gaps and shortcomings
No dataset is perfect. What matters is whether gaps are known, documented, and addressed. Regulators will look for gap logs, mitigation plans, and evidence of continuous improvement rather than unrealistic claims of completeness.
Article 10(3): Data Quality Criteria
Paragraph 3 introduces four deceptively simple requirements: datasets must be relevant, sufficiently representative, free of errors, and complete in light of the system’s intended purpose.
In enforcement terms, these are not abstract ideals. Regulators will expect statistical evidence, sampling analyses, error rates, and representativeness assessments. For systems affecting individuals or groups, this includes evaluating whether relevant populations are adequately represented.
This is where many organizations fail audits. Claims of representativeness without supporting metrics, or quality assurances without validation evidence, will not withstand scrutiny in 2026.
In practice: convert “relevant, representative, error-free, complete” into measurable thresholds, then document why those thresholds fit the system’s intended purpose and reflect a state-of-the-art approach.
Link to Article 8: These quality criteria should be defined and justified in light of the intended purpose and the generally acknowledged state of the art (Article 8).
Article 10(4): Contextual Adaptation
Paragraph 4 requires datasets to reflect the specific geographical, behavioural, or functional context in which the AI system is used. A dataset that is compliant in one context may be non-compliant in another.
For example, a credit scoring model trained primarily on non-EU consumer data may fail to reflect EU-specific socioeconomic patterns. Similarly, behavioral data collected in one cultural context may not generalize safely to another.
This provision forces organizations to confront localization risk. Deploying a “one-size-fits-all” model across jurisdictions without contextual adaptation creates immediate exposure under Article 10.
In practice: treat geographic or behavioural context shifts as a trigger to refresh datasets, re-run representativeness checks, and update evidence — not as a one-time pre-launch task.
Article 10(5): Exceptional Use of Sensitive Data
Paragraph 5 allows the processing of special categories of personal data solely for bias detection and correction — and only when strictly necessary. This is an exception, not a loophole.
Organizations must demonstrate that no less intrusive alternatives exist, apply strong safeguards such as pseudonymisation, restrict re-use, and delete data once the bias issue is addressed. All such processing must be documented and defensible.
Improper use of sensitive data under the guise of bias mitigation is likely to attract intense scrutiny from both AI Act and GDPR regulators.4
Article 10(6): Systems Without Model Training
Finally, paragraph 6 clarifies that systems not using training techniques are subject only to testing dataset requirements under paragraph 3. This does not eliminate obligations; it narrows them.
Even for these systems, testing data must still meet relevance, representativeness, error-free, and completeness criteria. In practice, this ensures baseline data quality even where models are rule-based or deterministic.
Taken together, Article 10 establishes a clear message for 2026: high-risk AI compliance begins with disciplined, transparent, and well-documented data governance. Anything less is unlikely to survive regulatory examination.
3. Key Themes Decoded: Data Quality, Lineage, and Bias Mitigation Under Article 10
Although Article 10 is written as legal paragraphs, enforcement tends to cluster around a few practical questions. In practice, most reviews come down to three themes: data quality, data lineage, and bias mitigation. Together, they reveal whether governance is real—or whether it only exists in a document.
Understanding these themes — and how they translate into evidence — is essential for organizations preparing for August 2, 2026.
Data Quality: From Abstract Standard to Measurable Control
Article 10’s requirement that datasets be “relevant, sufficiently representative, free of errors, and complete” is intentionally broad. Regulators expect providers to translate these standards into measurable criteria that fit the system’s intended purpose.
Relevance means the data directly supports the task the AI system is designed to perform. For example, historical hiring data may be relevant for predicting job performance signals but irrelevant — and risky — if it encodes outdated organizational practices or biased decision-making patterns.
Representativeness goes beyond demographic balance. It includes temporal coverage, edge cases, and operational conditions. A dataset that performs well during testing but fails under real-world variability will raise immediate red flags during audits.
Error-free does not mean perfect. Regulators recognize that all datasets contain noise. What matters is whether error rates are known, monitored, and managed. Undocumented error tolerance is often treated as negligence rather than oversight.
Completeness is contextual. Missing attributes, incomplete records, or inconsistent labeling must be evaluated against system impact. In high-risk use cases, incomplete data that affects protected groups or safety outcomes can invalidate compliance claims.
In 2026, quality assertions without metrics are unlikely to survive scrutiny. Expect auditors to request sampling analyses, validation reports, and documented thresholds that define what “acceptable quality” means for your system.
Data Lineage: The Backbone of Proving Compliance
If data quality defines what “good data” looks like, data lineage proves how that data moved through the system. Article 10 does not explicitly use the term “lineage,” but its requirements are impossible to meet without traceability.
Data lineage answers fundamental compliance questions: Where did the data originate? How was it transformed? Which versions were used for training, validation, and testing? What changes occurred over time?
In enforcement scenarios, lineage failures are often more damaging than quality gaps. An organization may claim robust governance, but without lineage evidence, regulators cannot verify those claims. This is why traceability has become a central compliance concern rather than a purely technical one.
Lineage must extend across the full lifecycle: raw sources, preprocessing pipelines, feature engineering, model versions, deployment contexts, and post-deployment updates. Manual tracking rarely scales beyond small pilots, which is why many organizations are now adopting automated lineage tooling ahead of 2026.
For high-risk systems, lineage is not a one-time artifact. It is a living record that supports audits, incident investigations, and post-market monitoring. Without it, even well-designed systems become compliance liabilities.
Bias Mitigation: Examination, Action, and Proof
Bias mitigation is one of the most misunderstood aspects of Article 10. The regulation does not demand bias-free systems — a technically unrealistic standard. Instead, it requires structured examination, documented mitigation, and ongoing vigilance.
The first obligation is examination. Organizations must actively assess datasets for biases that could lead to discriminatory or harmful outcomes. This includes statistical imbalance, proxy variables, historical discrimination, and contextual mismatches.
The second obligation is mitigation. When bias risks are identified, providers must take reasonable steps to reduce them. These steps may involve re-sampling, re-weighting, feature review, algorithmic constraints, or post-processing corrections. The chosen approach must be appropriate to the system’s risk profile and documented accordingly.
The third obligation is proof. Regulators will not accept verbal assurances that bias was “considered.” They will look for records showing what was tested, what was found, what was changed, and why remaining risks were deemed acceptable.
Article 10’s allowance for exceptional processing of sensitive data underscores this point. The exception exists precisely because meaningful bias detection sometimes requires access to protected attributes. However, misuse of this exception — or failure to document safeguards — creates significant legal exposure.
Common Article 10 Pitfalls Emerging in 2026
As organizations prepare for enforcement, several recurring pitfalls are becoming apparent.
One is the use of shadow datasets — data copied, inherited, or augmented outside formal governance processes. These datasets often lack clear provenance and undermine compliance claims.
Another is fragmented ownership. When data governance responsibilities are split across teams without clear accountability, gaps emerge between policy and practice.
A third pitfall is over-reliance on static documentation. Article 10 is not satisfied by a one-time report created before deployment. Ongoing monitoring, updates, and evidence refresh are essential, especially as systems evolve post-launch.
Recognizing these patterns early allows organizations to shift from reactive remediation to proactive governance — a distinction regulators increasingly reward in enforcement decisions.
4. A 7-Step Implementation Guide for Article 10 Compliance Before August 2, 2026
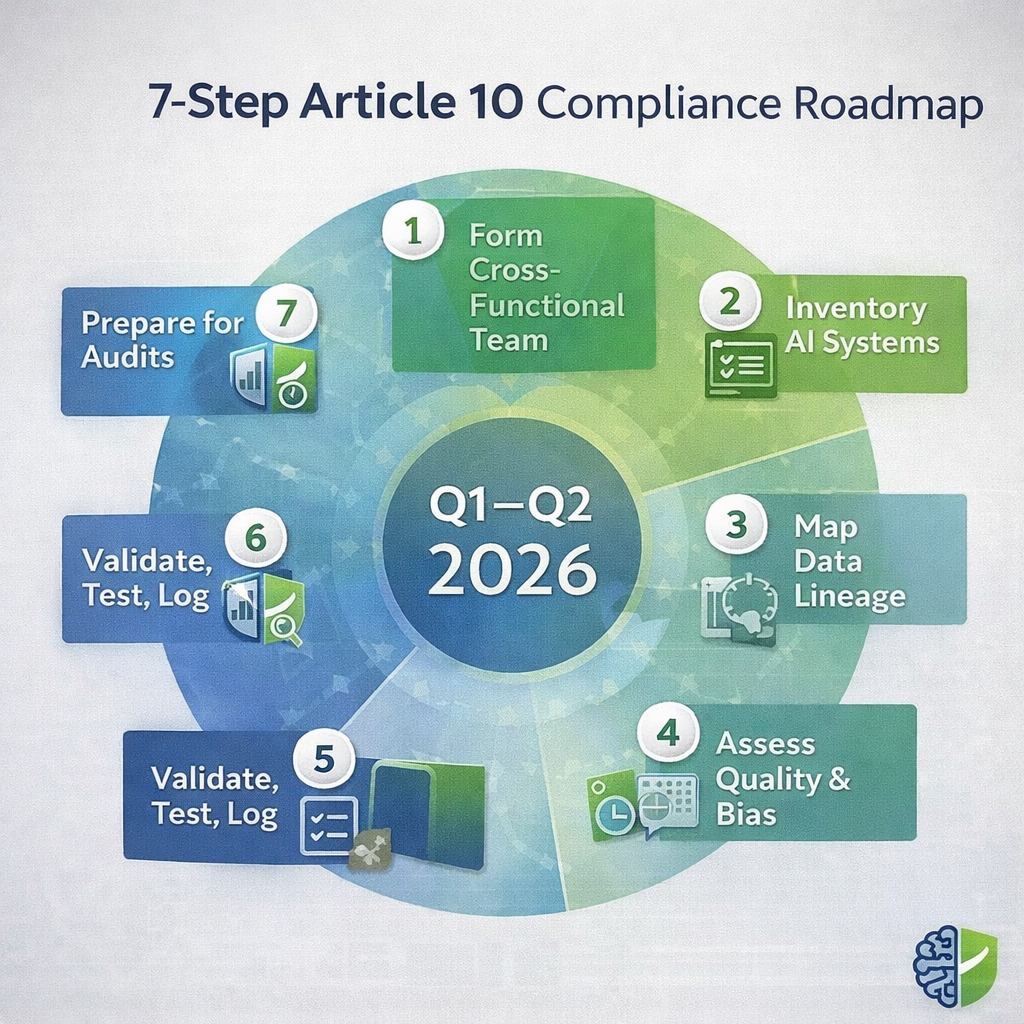
Understanding Article 10 is only the first step. The real challenge for organizations deploying high-risk AI systems is turning legal requirements into repeatable, auditable operational practices. As August 2, 2026 approaches, regulators will focus less on intent and more on whether concrete controls are already in place.
The seven steps below reflect what a credible Article 10 programme looks like in practice. They’re designed to be sequence-driven and realistic to execute before the August 2026 deadline—especially if you start early and treat evidence as a deliverable, not an afterthought.
Step 1: Scope and Classify All Relevant Datasets
Article 10 obligations attach to datasets used for training, validation, and testing in high-risk AI systems. The first step is therefore scoping. Organizations must identify which datasets fall within scope and how they are used across the model lifecycle.
This includes distinguishing between datasets used for model training and those used only for testing or validation, as the regulatory burden differs. Many organizations discover at this stage that legacy or inherited datasets are still actively influencing high-risk systems.
The output of this step should be a definitive dataset inventory mapped to each high-risk AI system, including purpose, usage phase, and ownership.
Step 2: Establish a Formal Data Governance Framework
Article 10 assumes that data governance is not ad hoc. Providers must demonstrate structured governance practices that define roles, responsibilities, and decision-making authority over datasets.
This typically includes assigning data owners, defining approval workflows for dataset changes, and establishing escalation paths when quality or bias risks are identified. Governance frameworks that exist only as policy documents but are not embedded into workflows are unlikely to satisfy enforcement expectations.
By early 2026, regulators will expect governance to be operational — not aspirational.
Step 3: Implement End-to-End Data Lineage Tracking
Lineage is the connective tissue of Article 10 compliance. Without it, quality and bias controls cannot be verified. Organizations should implement automated lineage tracking that captures data origin, transformations, feature engineering steps, and dataset versioning.
This lineage must be continuous, not snapshot-based. Changes to datasets, preprocessing logic, or feature definitions should be recorded automatically, creating an audit-ready trail that can be reviewed months or years later.
In practice, this is where many organizations shift from spreadsheets to dedicated lineage or observability tooling, particularly for systems operating at scale.
Step 4: Assess Data Quality and Representativeness
Once lineage is in place, quality assessment becomes measurable. Organizations should define explicit quality criteria aligned with the system’s intended purpose and risk profile.
This includes evaluating relevance, representativeness, completeness, and known error rates. Statistical profiling, sampling audits, and representativeness checks should be documented and repeatable.
Importantly, quality assessments should not be treated as one-time gates. Regulators increasingly expect evidence that quality is monitored over time, especially when data pipelines are dynamic.
Step 5: Conduct Bias Examination and Mitigation
Bias examination under Article 10 is not optional. Providers must actively assess whether datasets introduce risks of discriminatory or harmful outcomes.
This involves selecting appropriate bias metrics, testing across relevant population groups, and identifying proxy variables that may encode protected characteristics indirectly. When risks are identified, mitigation measures must be applied and justified.
Where exceptional processing of sensitive data is used to detect or mitigate bias, strict safeguards must be documented. Regulators will closely examine whether this processing was necessary, proportionate, and time-limited.
Step 6: Document Decisions, Gaps, and Residual Risks
Article 10 compliance is proven through documentation. Every significant decision — including accepted limitations — should be recorded.
This includes documenting why certain datasets were deemed representative, how quality thresholds were set, what bias mitigation techniques were applied, and which risks remain unresolved. Gaps that cannot be closed before deployment must be explicitly acknowledged rather than ignored.
These records should feed directly into technical documentation, Records of Processing Activities, and conformity assessment materials.
Step 7: Test, Review, and Rehearse Before Enforcement
The final step is validation. Organizations should conduct internal dry runs simulating regulatory scrutiny. This includes reviewing whether dataset lineage can be reconstructed, whether quality and bias evidence is easily accessible, and whether responsible teams can explain governance decisions clearly.
Dry runs often reveal weak points that are invisible during day-to-day operations. Addressing these issues in Q1–Q2 2026 significantly reduces enforcement risk once high-risk obligations become fully applicable.
By the time August 2, 2026 arrives, Article 10 compliance should already be a routine operational process — not an emergency response.
5. Tools, Best Practices, and Enforcement Risks Under Article 10
Article 10 is a legal requirement, but you meet it through operations and tooling. Regulators won’t tell you which vendor to buy. They will, however, expect your organisation to show that your stack can support ongoing data governance, lineage, and bias controls—at scale, over time, and with evidence you can actually retrieve when asked.
In practice, most high-risk AI providers are converging on a layered approach that combines open-source components with enterprise governance platforms, depending on scale, risk exposure, and regulatory maturity.
Recommended Tooling Patterns for Article 10 Compliance
At a minimum, an Article 10-ready stack should support three core capabilities: data quality validation, lineage and traceability, and bias detection and monitoring. These capabilities do not need to reside in a single platform, but they must integrate cleanly and produce consistent evidence.5
| Capability | Purpose Under Article 10 | Common Tooling Examples | Compliance Value |
|---|---|---|---|
| Data Quality Validation | Assess relevance, completeness, error rates | Great Expectations, Pandera, custom statistical checks | Demonstrates dataset fitness and ongoing control |
| Data Lineage & Provenance | Trace datasets from source to deployment | OpenLineage, MLflow, enterprise data catalogs | Enables audit reconstruction and accountability |
| Bias Detection & Mitigation | Examine and reduce discriminatory risks | Fairlearn, AIF360, custom bias metrics | Supports Article 10 bias examination duties |
| Governance & Documentation | Centralize evidence and decisions | Governance platforms, controlled repositories | Feeds conformity assessment and technical files |
What matters most from an enforcement perspective is not brand selection, but whether these tools are actually used, maintained, and connected to governance workflows. Disconnected tooling that produces evidence no one reviews is unlikely to satisfy regulators.
What matters under audit: evidence should be easy to retrieve and consistently linked to risk decisions — not scattered across disconnected tools, ad hoc spreadsheets, or undocumented judgement calls.
Common Article 10 Compliance Failures Observed by Regulators
Based on early audits, guidance drafts, and enforcement signals across adjacent regulatory regimes, several recurring failure patterns are already emerging:
- Datasets cannot be reliably traced back to their origin or preprocessing steps
- Bias assessments are informal, undocumented, or limited to development phases only
- Quality checks exist but are not repeated as data pipelines evolve
- Assumptions about representativeness are asserted rather than tested
- Exceptional sensitive data processing is used without documented safeguards
These failures are not usually the result of bad faith. They arise from fragmented ownership, legacy data pipelines, and governance models that were never designed for regulatory scrutiny.
Enforcement Exposure and Financial Risk
Non-compliance with Article 10 carries meaningful enforcement consequences. Under the EU AI Act, failures related to data governance obligations can trigger administrative fines of up to 4% of global annual turnover, depending on severity and duration.
Beyond financial penalties, regulators may require corrective actions such as dataset withdrawal, model retraining, deployment suspension, or market removal. These measures often have a greater operational and reputational impact than fines themselves.
Crucially, enforcement assessments will focus on whether organizations took reasonable, documented steps to comply. In borderline cases, strong evidence of governance effort can significantly influence regulatory outcomes.
Conclusion: Article 10 Is the Backbone of Trustworthy High-Risk AI
Article 10 is not a peripheral technical requirement. It is the foundation upon which the EU AI Act’s vision of trustworthy, high-risk AI is built. Without robust data governance, claims of fairness, robustness, and accountability cannot be substantiated.
As August 2, 2026 approaches, organizations deploying high-risk AI systems face a clear choice. They can treat data governance as an abstract compliance obligation and risk enforcement failure, or they can embed lineage, quality controls, and bias mitigation into everyday operations.
The latter approach is not only safer from a regulatory perspective, but also strategically stronger. Organizations with mature data governance are better positioned to explain system behavior, respond to incidents, and adapt to evolving regulatory expectations.
For compliance officers, legal teams, and data leaders, the work must begin now. Article 10 readiness cannot be achieved in the final weeks before enforcement. It requires deliberate scoping, tooling, documentation, and rehearsal well in advance.
To support this process, we have developed a structured self-assessment tool that translates Article 10 requirements into a practical dataset-level checklist. It is designed to help teams identify gaps, document controls, and prepare evidence before regulators ask.
If you’ve made it this far, you already understand the real challenge with EU AI Act Article 10:
it’s not about knowing the rule — it’s about proving you can demonstrate data quality, bias controls,
and lineage traceability with evidence under audit.
To help you turn the guidance in this post into an actionable workflow, we put together a printable, audit-ready checklist
you can use with your compliance, data governance, and engineering teams.
EU AI Act Article 10 — Data Quality & Lineage Compliance Checklist (2026 Edition)
A practical toolkit to document dataset scope, origin controls, preparation/annotation governance, quality &
representativeness testing, lineage traceability, ownership & oversight, and post-market monitoring — built for
high-risk AI systems preparing for August 2026 enforcement.
- ✅ Step-by-step control checks aligned to Article 10 expectations
- ✅ Evidence log template for audit defensibility
- ✅ Final readiness review + attestation page
- ✅ Appendix: sample lineage mapping diagram template
Tip: Save a completed version in your compliance repository alongside your dataset documentation and lineage records.
That’s usually what regulators ask for first.
Preview the PDF (optional)
References
- European Parliament and Council of the European Union. (2024).
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act).
Official Journal of the European Union.
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
↩ - European Parliament and Council of the European Union. (2024).
Artificial Intelligence Act, Article 99 (Administrative fines).
EUR-Lex.
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
↩ - European Parliament and Council of the European Union. (2024).
Artificial Intelligence Act, Article 10 (Data and Data Governance).
EUR-Lex.
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
↩ - European Parliament and Council of the European Union. (2016).
Regulation (EU) 2016/679 (General Data Protection Regulation), Article 9(1).
EUR-Lex.
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32016R0679
↩
Covering responsible AI, governance frameworks, policy, ethics, and global regulations shaping the future of artificial intelligence.