
Human oversight is now one of the most frequently invoked ideas in AI governance, yet in practice it remains one of the least carefully implemented. In policy documents, procurement notes, model cards, and board briefings, the phrase often appears as if its meaning were self-evident. Put a person somewhere near the system, require a manual check before a high-stakes output is finalized, add a review queue, and the problem seems solved. In practice, that is usually where the real trouble begins. A human reviewer who lacks authority, context, timing, or technical understanding does not create control. At best, that person becomes a witness to automated decision-making. At worst, they become the last fragile layer in front of a predictable failure.
The deeper problem is that many organizations still treat oversight as a symbolic safeguard rather than an engineered capability. That assumption has become increasingly difficult to defend. The regulatory direction is now unmistakable. Under Article 14 of the EU Artificial Intelligence Act, human oversight is not framed as a decorative ethical principle but as a concrete requirement for high-risk AI systems.[1] The official text of Regulation (EU) 2024/1689 places oversight inside the operational architecture of lawful AI deployment, alongside risk management, data governance, transparency, record-keeping, and robustness requirements.[2] In other words, the law does not ask whether a human exists somewhere in the workflow. It asks whether meaningful human oversight has been designed in a way that can actually prevent or reduce risks to health, safety, and fundamental rights.
That distinction matters more than many teams admit. In several sectors, the myth of “human in the loop” has already been punctured by lived experience. Credit adjudication systems have produced outputs that reviewers approved too quickly because the model appeared more certain than it really was. Decision-support tools in public administration have shaped case outcomes through inertia rather than explicit accountability. Clinical and diagnostic environments have shown, again and again, that human reviewers under time pressure are prone to automation bias, especially when the interface is persuasive and the model’s limitations are poorly signaled. The language of oversight survives in all of these settings, but the control itself is thin. Oversight in name is not oversight in fact.
That is why serious work on human oversight has to begin beyond slogans. The real question is not whether a person touches the process. It is whether that person can understand what the system is doing, identify when something is wrong, intervene in a meaningful way, and carry enough institutional authority for that intervention to matter. That immediately turns oversight into a design problem, a governance problem, a training problem, and a documentation problem all at once. It also means there is no single oversight model that fits every deployment. A human reviewing every decision in a low-volume, high-stakes medical setting is not performing the same function as a supervisor auditing a stream of credit decisions, and neither of them occupies the same position as an executive or public authority that retains ultimate authority over system use. Those differences need to be explicit rather than blurred together under one fashionable phrase.
In research and regulatory analysis, three related models usually surface. The first is human-in-the-loop, where a human actively participates in the decision process itself. The second is human-on-the-loop, where a human supervises system behavior and intervenes when necessary. The third is human-in-command, where ultimate authority remains with human decision-makers even if the system operates with a higher degree of autonomy in practice. Those distinctions are not semantic. They determine review burden, staffing needs, interface design, escalation mechanisms, and legal accountability. They also shape what sort of evidence an organization will need when it claims that oversight is effective rather than performative.
That last point is where many governance programs still stumble. A great deal of “responsible AI” writing remains too abstract to help teams build an operational framework. It speaks in terms of trust, values, or principles, then retreats before the practical questions arrive. Who reviews what, and when? Under what conditions is intervention mandatory rather than optional? What information must be visible to the reviewer in the moment of decision? How should overrides be logged? What training must an overseer receive before being trusted with a high-risk system? How should organizations measure whether oversight is actually functioning, instead of merely existing in policy text? In practice, the difference between a credible oversight framework and a weak one usually appears in those operational details.
The legal environment has also matured enough that these details can no longer be postponed. The NIST Artificial Intelligence Risk Management Framework treats human-AI interaction as a governance issue tied to trustworthiness, risk management, and ongoing evaluation.[3] International policy frameworks have reinforced this direction. The OECD Principles on Artificial Intelligence emphasize human-centred values and the need for appropriate human oversight in AI systems.[4] Industry practice has moved in the same direction, even if unevenly. Technical explanations of human-in-the-loop systems in industry literature highlight the operational logic behind maintaining human participation in automated decision pipelines.[5] At the same time, governance researchers have warned that superficial review mechanisms can create only the appearance of accountability rather than genuine control.[6] The direction of travel is clear: oversight has to be engineered, not presumed.
What follows takes that premise seriously. The aim is not to romanticize the human role or pretend that manual review is automatically safer than automation. Humans are inconsistent, overloaded, and susceptible to institutional pressure. Oversight can fail because the reviewer is undertrained, because the model’s outputs are hard to interpret, because organizational incentives reward speed over caution, or because the system was never designed to make intervention practical in the first place. But these are reasons to build better oversight, not reasons to abandon it. Well-designed human oversight does not ask a person to rescue a broken system through intuition alone. It gives them the authority, information, timing, and procedural backing needed to make control real.
That is the central argument of this article. Effective human-in-the-loop oversight is not a checkbox at the end of an AI workflow. It is a layered governance framework that allocates authority, structures intervention, and embeds human judgment where the risk profile of the system demands it. That framework has to be tailored to the deployment context, tested under stress, documented in a way regulators can review, and sustained over time as systems evolve. For high-risk AI, that is no longer aspirational governance language. It is operational design.
Understanding Human Oversight in AI Governance
The phrase “human oversight” is often used too loosely to be useful. In regulatory and operational work, precision matters. A person occasionally glancing at outputs is not the same as a reviewer who must approve every high-stakes result before action is taken. A supervisor who can pause a model during abnormal behavior is not equivalent to a governing body that decides whether the system should be used at all. Once those roles are separated, oversight becomes easier to design and much harder to fake.
Human-in-the-loop, properly understood, refers to a setup in which human intervention is built directly into the decision process. The human is not merely observing outcomes after the fact. They are actively participating in approval, correction, or rejection before the system’s output becomes operational. This model often appears in domains where the tolerance for error is low and the volume of decisions remains manageable. Healthcare decision support, parts of public administration, and certain financial determinations are frequent examples. The attraction of HITL is obvious: it preserves a live point of human judgment at the moment risk is most concentrated. Its weakness is just as obvious. If the volume is too high, the interface too poor, or the reviewer too constrained, the human role degrades into ritual.
Human-on-the-loop is different. Here the system can act with a greater degree of autonomy, but human supervisors remain responsible for monitoring performance and intervening when necessary. This model is often more realistic in environments where full manual review would be impractical. It depends heavily on the quality of alerts, dashboards, thresholds, and override mechanisms. A human-on-the-loop arrangement only works if anomalous behavior is visible soon enough for intervention to matter. Otherwise, supervision becomes retrospective rather than preventive.
Human-in-command sits at another level. It is less about line-by-line intervention and more about preserving ultimate authority over the conditions, boundaries, and legitimacy of system use. In practice, this means humans remain responsible for whether a system is deployed, under what constraints, with which fallback procedures, and with what termination authority if risks become unacceptable. In mature governance structures, HIC does not replace HITL or HOTL. It sits above them, ensuring the organization never confuses operational autonomy with normative authority.
Article 14 of the EU AI Act is important because it forces this conversation out of abstraction. The provision requires high-risk AI systems to be designed and developed in such a way that they can be effectively overseen by natural persons during the period in which they are in use. That oversight is meant to prevent or minimize risks to health, safety, and fundamental rights, including in conditions of reasonably foreseeable misuse. It also points toward practical requirements that organizations too often underinvest in: the ability of overseers to understand the system’s capabilities and limitations, detect anomalies, remain alert to automation bias, and intervene or stop the system where appropriate. None of that happens automatically just because a human is present in the workflow.
The EU approach is not isolated. NIST’s AI RMF frames human oversight within a broader risk management structure in which trustworthy AI depends on governance, context awareness, measurement, and ongoing management rather than static technical claims alone. The OECD principles likewise connect trustworthy AI to human-centred values and appropriate safeguards. The convergence across these frameworks is striking. They differ in legal force and institutional setting, but they are moving toward the same practical conclusion: meaningful oversight requires human agency to be made operational.
That also means providers and deployers cannot hide behind one another. Providers are expected to design systems in a way that makes human oversight possible. Deployers, especially in high-risk contexts, are expected to use those systems under conditions where oversight can actually be exercised. That distinction is often glossed over in public discussion. A provider cannot satisfy Article 14 with vague instructions that a deployer should “use human judgment,” while a deployer cannot claim oversight exists if reviewers are given neither usable information nor real authority. Meaningful oversight lives in the interaction between design and use.
The sharpest critique of weak oversight frameworks is that they produce what some researchers and advocates have described, in different formulations, as the “human lost in the queue” problem. The human is nominally present, but overloaded, deskilled, ignored, or systematically nudged toward endorsement. This is where rubber-stamping becomes more than an insult. It becomes a governance diagnosis. A human who cannot realistically question the output, pause the process, or justify an override is not exercising control. They are absorbing liability on behalf of a system that remains effectively unchecked.
That is why the real debate is not whether to keep humans involved. It is how to design oversight so that human judgment remains both meaningful and accountable. That requires more than policy language. It requires explicit choices about where intervention happens, what evidence is available at the moment of review, how authority is distributed, how disagreement with the model is handled, and how the organization measures whether its oversight process is alive or merely ceremonial. From there the article moves into the harder part: what an effective framework actually looks like when designed for high-risk AI systems rather than for conference slides.
Design Principles for Human-in-the-Loop Oversight Frameworks
Once the terminology surrounding oversight becomes precise, the design challenge becomes unavoidable. Human oversight cannot simply be appended to an automated system after the technical architecture has been completed. Oversight must be designed alongside the system itself. In practice this means the ability of a human to interpret outputs, intervene in workflows, and halt operations when necessary must be considered during the earliest stages of system design. When oversight is introduced only after deployment, the human role often becomes reactive, constrained, or symbolic. Effective frameworks treat human participation as a structural component of the system rather than an afterthought.
The first principle is proportionality. Oversight intensity must reflect the risk profile of the AI system involved. A recommender system suggesting content in a low-stakes environment may require monitoring and periodic auditing, but not continuous manual review. A credit scoring engine, medical diagnostic tool, biometric identification system, or public-sector decision system carries far greater implications for individuals and institutions. In those environments, oversight frameworks must be deeper, more explicit, and more rigorously documented. The EU AI Act itself reflects this logic through its risk-based structure, particularly the classification of high-risk systems listed in Annex III.
The second principle concerns human capability. Oversight assumes that the individuals responsible for supervising the system possess sufficient competence to interpret outputs and understand limitations. This requirement appears explicitly in the regulatory language surrounding human oversight. An overseer must be able to detect anomalies, interpret confidence levels or decision signals, and recognize when a system’s output should be challenged. Without that competence, oversight collapses into procedural compliance. Organizations sometimes underestimate the training burden associated with this role. In practice it often requires a combination of domain knowledge, system familiarity, and awareness of cognitive biases such as automation bias or confirmation bias.
The third principle is interpretability in context. Oversight only works when the interface presented to human reviewers actually supports informed judgment. If an AI system produces opaque outputs without contextual signals, the reviewer cannot meaningfully question the result. Effective oversight interfaces therefore expose relevant explanatory cues: model confidence ranges, uncertainty signals, historical comparison points, anomaly alerts, or traceable reasoning paths where possible. Explainable AI techniques can support this function, but equally important is thoughtful interface design that allows humans to understand when they should intervene.
The fourth principle involves authority. Oversight without authority is governance theatre. The individuals tasked with reviewing AI outputs must possess the institutional authority to intervene when concerns arise. That authority may involve rejecting outputs, escalating the case, triggering manual review procedures, or suspending the system under defined conditions. Organizational structures sometimes undermine this authority unintentionally. For example, if performance metrics reward speed and throughput while penalizing overrides, reviewers may hesitate to challenge automated outputs even when concerns exist. Effective frameworks therefore align oversight authority with organizational incentives and escalation mechanisms.
A fifth principle relates to traceability. Oversight decisions must be observable and auditable. This means every intervention, override, or review decision should generate a record explaining why the action occurred. These records become essential evidence during internal audits, regulatory reviews, or post-incident investigations. Traceability also supports organizational learning. Patterns of frequent overrides may indicate weaknesses in the model itself, data drift, or gaps in training data. Without systematic logging of oversight decisions, these signals remain invisible.
Finally, oversight frameworks must integrate across the lifecycle of an AI system. Oversight is often discussed as a deployment-phase mechanism, but its foundations appear much earlier. During model development, design choices determine how interpretable outputs will be and what signals will be available to reviewers. During deployment, operational procedures determine how often human intervention occurs and under what conditions escalation is required. During post-deployment monitoring, oversight activities intersect with broader governance processes such as performance monitoring, risk assessment, and incident reporting. A well-structured governance program ensures these phases remain connected rather than fragmented.
Oversight Models in Practice
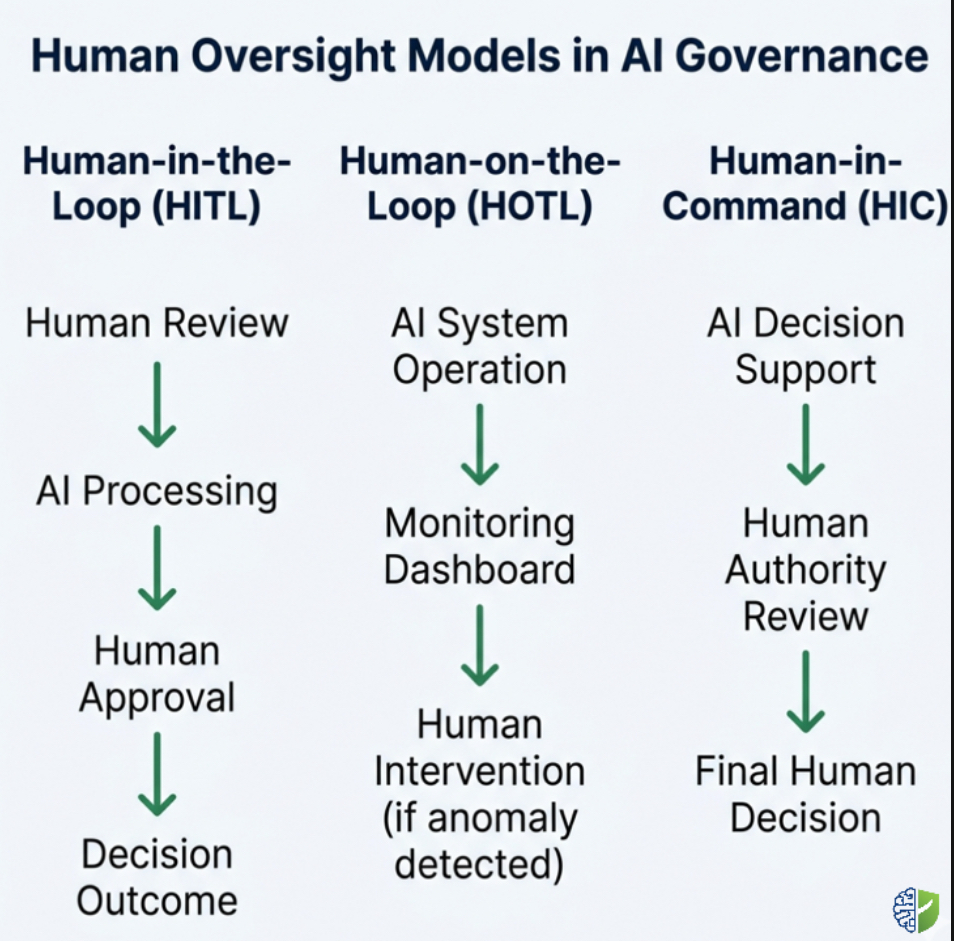
In operational settings, oversight usually follows one of three structural models. These models do not represent mutually exclusive choices. Many mature governance systems combine them at different layers of control. Understanding their distinctions helps organizations design oversight mechanisms that match the risks of a particular deployment environment.
| Oversight Model | Description | Typical Context | Advantages | Challenges |
|---|---|---|---|---|
| Human-in-the-Loop (HITL) | Human intervention occurs directly within the decision workflow before the AI output becomes operational. | Healthcare diagnostics, credit approvals, legal or public-sector determinations. | Strong direct control over high-stakes decisions. | Scalability constraints and risk of reviewer fatigue. |
| Human-on-the-Loop (HOTL) | Human supervisors monitor system behaviour and intervene when anomalies or thresholds are triggered. | Fraud detection systems, large-scale transaction monitoring, operational analytics. | Balances automation efficiency with supervisory control. | Requires well-designed alerts and monitoring tools. |
| Human-in-Command (HIC) | Humans retain ultimate authority over whether and how the system operates, including deployment decisions. | Strategic governance, regulatory oversight, organizational AI governance boards. | Preserves institutional accountability and strategic control. | Requires clear governance structures and decision rights. |
These models should not be treated as interchangeable labels. Each represents a different balance between automation and human judgment. HITL places human review at the decision boundary itself. HOTL shifts the human role toward supervision and anomaly response. HIC ensures the broader governance environment remains anchored in human authority even as operational systems become more autonomous. Effective governance frameworks frequently combine all three. A system may operate with HOTL supervision during routine operations while retaining HITL review for particularly sensitive decisions and HIC oversight at the organizational level.
Designing the appropriate mix requires a realistic assessment of operational context. High-risk AI systems frequently require multiple oversight layers precisely because the risks they pose cannot be reduced to a single intervention point. A biometric identification system, for example, may include automated matching processes monitored by supervisors while requiring human verification before final action is taken. Financial risk models may operate continuously under supervisory oversight but escalate unusual cases for direct human evaluation. The key insight is that oversight is rarely a single mechanism. It is an architecture of interacting safeguards.
The regulatory discussion around oversight increasingly reflects this architectural perspective. Regulators are less interested in whether a human appears somewhere in the workflow and more interested in whether oversight mechanisms can realistically detect problems and intervene in time to prevent harm. That emphasis explains why documentation requirements now frequently extend beyond policy language to include interface design, training procedures, escalation rules, and monitoring systems. Oversight becomes measurable only when these elements are visible.
Organizations that treat oversight as a living operational capability tend to approach the problem differently from those that treat it as a compliance checkbox. They invest in reviewer training programs, design decision interfaces that surface meaningful signals, test intervention mechanisms through simulations, and monitor how often humans override automated outputs. These practices gradually transform oversight from a fragile procedural layer into a functional control system. As AI deployments expand across sectors, this shift from symbolic oversight to engineered oversight is becoming one of the defining challenges of responsible AI governance.
Operationalizing Human-in-the-Loop Oversight
Translating oversight principles into operational practice requires deliberate design choices. The moment an organization decides that human judgment must remain part of the decision architecture, it must determine where that intervention occurs, what information is available to the human reviewer, and how the organization responds when the reviewer disagrees with the system. These questions often appear deceptively simple in policy discussions but become much more complex once they intersect with real operational environments.
Most high-risk AI deployments involve multiple decision stages rather than a single automated output. Data enters the system through preprocessing pipelines, model inference generates outputs, downstream applications transform those outputs into recommendations or actions, and human actors interact with the results in various ways. Oversight frameworks therefore begin with mapping these stages and identifying the points at which human judgment should intervene. In some cases the intervention occurs before the model processes sensitive inputs. In other cases it occurs after the model generates an output but before that output triggers a real-world action. The placement of the human role determines both the effectiveness and the cost of oversight.
The first practical step is a structured assessment of the system’s risk profile. Organizations deploying high-risk AI systems must examine not only the potential severity of harm but also the probability of erroneous or biased outcomes. This assessment determines how frequently human oversight should occur and what form it should take. A diagnostic AI system influencing medical treatment decisions demands a far more immediate and consistent human presence than an internal analytics model used for forecasting. Risk classification therefore shapes the oversight architecture long before the system reaches production.
Once risk classification has been established, oversight points within the workflow must be defined. These points represent moments where human judgment can confirm, adjust, or reject automated outputs. In practice they often appear in several forms. Some systems require manual validation before certain outputs are finalized. Others flag decisions that exceed defined risk thresholds, routing them to a human reviewer. Still others allow automated operation under normal conditions but require human approval for actions affecting sensitive populations or regulatory obligations. The design challenge is to ensure that intervention points occur early enough to prevent harm rather than merely documenting it afterward.
Technical interface design plays an equally important role. A reviewer cannot exercise meaningful oversight if the system presents outputs without context. Effective oversight interfaces provide a range of signals that help reviewers interpret the system’s reasoning. These may include confidence scores, anomaly indicators, model uncertainty metrics, historical comparison data, or explanations generated through interpretability techniques. Even simple visual cues can influence how effectively humans detect errors. An interface that highlights unusual model behaviour or conflicting indicators allows reviewers to identify problems more quickly than one that simply displays a final prediction.
The structure of the review process itself also deserves careful attention. Oversight frameworks often collapse when review responsibilities are poorly distributed. Assigning oversight to individuals who lack domain expertise or decision authority undermines the process immediately. Effective frameworks define oversight roles clearly, specifying who performs routine reviews, who handles escalations, and who ultimately decides whether the system continues operating under certain conditions. Many organizations formalize these roles through governance structures that resemble risk management committees or operational control groups.
Training is another factor that determines whether oversight functions effectively. Reviewers must understand the system’s intended purpose, its limitations, and the types of errors it may produce. Without this knowledge reviewers often rely excessively on automated outputs. This phenomenon, commonly described as automation bias, occurs when humans defer to algorithmic recommendations even when contradictory evidence exists. Oversight training programs therefore emphasize critical evaluation rather than passive approval. Reviewers must learn when skepticism is appropriate and how to escalate concerns without procedural friction.
Escalation pathways form the backbone of any serious oversight program. When a human reviewer identifies an anomaly or suspects that an output may be unreliable, the system must provide a clear route for intervention. This might involve requesting additional review from a specialist, triggering a secondary evaluation process, or temporarily suspending the automated workflow. Escalation procedures ensure that oversight decisions are not isolated events but part of a structured governance process. They also protect individual reviewers from organizational pressure that might otherwise discourage intervention.
Monitoring and logging mechanisms connect human oversight to broader governance processes. Every review decision should generate a traceable record indicating the reasoning behind acceptance, modification, or rejection of the automated output. These logs serve multiple purposes. They create accountability for oversight decisions, provide evidence for regulatory compliance, and supply valuable data for improving the system itself. If reviewers frequently override a particular type of prediction, that pattern may indicate weaknesses in training data or model assumptions.
Testing the oversight framework is a step that organizations sometimes overlook. Oversight mechanisms should be validated through simulations or controlled exercises before full deployment. For example, organizations can introduce synthetic anomalies into test environments to observe whether reviewers detect them and follow escalation procedures correctly. These exercises reveal weaknesses in both the system interface and the human training process. They also reinforce the idea that oversight is an operational capability requiring practice and refinement.
Documentation completes the oversight architecture. Under regulatory frameworks such as the EU AI Act, organizations must be able to demonstrate that oversight mechanisms exist and function as intended. Documentation therefore includes descriptions of oversight roles, intervention procedures, training requirements, and escalation rules. It also includes records generated during system operation. Together these elements form the evidence base showing that human oversight is not merely promised but implemented.
Oversight Workflow Architecture
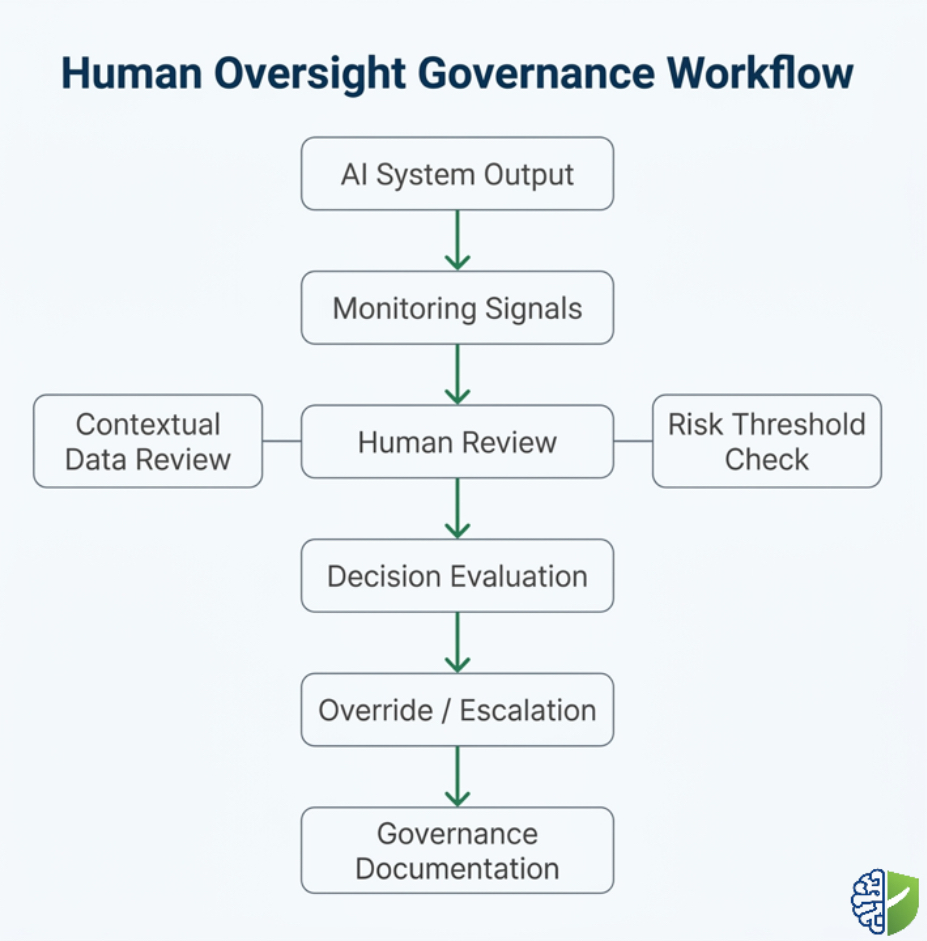
In operational environments, the oversight workflow typically follows a structured sequence of activities. Although the details vary between sectors, the general pattern remains consistent. A system generates outputs based on input data and model inference. Those outputs are evaluated against predefined thresholds or criteria that determine whether human intervention is required. Human reviewers then examine the output, considering both the automated prediction and contextual information. If the reviewer accepts the output, the system proceeds with the action. If concerns arise, the reviewer may modify the result, escalate the case, or halt the process entirely.
This workflow architecture allows organizations to maintain efficiency while preserving meaningful human judgment. Routine outputs can proceed with minimal friction, while high-risk or ambiguous cases receive additional scrutiny. The structure also supports transparency, because every stage of the process can be logged and reviewed. When regulators or auditors examine the system’s governance framework, they can observe how decisions moved through the oversight pipeline and where human intervention occurred.
Over time, oversight workflows evolve as organizations gain experience with their systems. Early deployments often rely on more intensive human review until confidence in model performance increases. Later stages may shift toward supervisory oversight models supported by monitoring tools and anomaly detection. This evolution does not eliminate human responsibility; it redistributes it. Even in highly automated environments, organizations remain responsible for ensuring that humans retain the ability to intervene when conditions change.
The transition from theoretical oversight to operational oversight therefore depends on careful coordination between technical design, organizational governance, and human capability. Systems that fail in one of these areas rarely sustain meaningful control. Effective frameworks recognize that oversight is not simply a task assigned to an individual. It is a distributed capability spanning technology, training, institutional authority, and continuous monitoring.
The Human Oversight Protocol Framework
Oversight becomes reliable only when it is formalized through a structured protocol. Many organizations speak about human oversight in broad terms but never translate those expectations into operational procedures. A protocol provides that missing structure. It defines the purpose of oversight, identifies who performs it, clarifies when intervention is required, and explains how decisions should be recorded. Without such a framework, oversight remains dependent on individual judgement and informal practice, which can vary widely across teams and operational contexts.
The concept of an oversight protocol is not unique to artificial intelligence governance. Similar structures have existed for decades in fields where automated systems interact with human decision-making. Aviation safety procedures, clinical review systems in healthcare, and financial risk oversight frameworks all rely on documented protocols describing how humans supervise complex technological systems. AI governance increasingly follows the same pattern. The protocol becomes the practical translation of regulatory expectations such as those outlined in Article 14 of the EU AI Act.
A well-designed oversight protocol typically begins with a clear statement of scope. This section identifies the systems covered by the framework and the types of decisions that require oversight. For high-risk AI systems, the scope definition usually references the system’s intended purpose, operational context, and potential impact on individuals or institutions. Explicit scope boundaries prevent confusion about where oversight responsibilities begin and end.
The next component addresses roles and responsibilities. Oversight frameworks function effectively only when the individuals responsible for supervision understand their authority and obligations. Governance programs often adopt a structured responsibility model similar to the RACI approach used in project management and risk governance. In such models, one group may be responsible for conducting reviews, another accountable for final decisions, and others consulted or informed depending on the situation. Clarifying these roles prevents oversight from becoming fragmented across multiple teams.
Oversight Roles and Responsibilities
| Role | Primary Responsibility | Typical Participants |
|---|---|---|
| Operational Reviewer | Examines AI outputs and determines whether they meet defined decision criteria. | Domain specialists, trained reviewers, operational analysts. |
| Oversight Supervisor | Handles escalated cases and ensures that oversight procedures are followed. | Risk managers, senior analysts, governance officers. |
| AI Governance Lead | Maintains the oversight framework and coordinates oversight policy across the organization. | AI governance teams, compliance leaders. |
| Executive Authority | Retains ultimate authority over whether the system continues operating under defined conditions. | Senior management, governance committees. |
After roles have been defined, the protocol must describe the procedures used to conduct oversight reviews. These procedures outline how reviewers interact with the system, what signals they examine, and under what conditions intervention is required. In practice, procedures often include defined decision criteria that help reviewers interpret outputs. These criteria may reference model confidence thresholds, contextual information about the case, or domain-specific rules that guide decision-making.
Decision criteria should be written carefully. Oversight frameworks that rely entirely on subjective judgement place an unnecessary burden on reviewers and introduce inconsistency into the process. On the other hand, overly rigid rules may prevent reviewers from exercising professional judgement when unusual situations arise. Effective protocols therefore combine structured criteria with discretionary authority, allowing reviewers to escalate cases when uncertainty exists.
Decision Criteria Example
| Condition Observed | Reviewer Action |
|---|---|
| Model output falls within standard confidence range | Proceed with normal workflow review. |
| Output falls below defined confidence threshold | Request additional evaluation or manual analysis. |
| Output conflicts with known contextual indicators | Escalate to supervisory review. |
| System behaviour appears anomalous or inconsistent | Pause automated process and trigger investigation. |
Escalation pathways form the next essential component of the protocol. Oversight does not end when a reviewer identifies a problem. The framework must specify how the organization responds. Escalation procedures define which team receives the case, how quickly a response is required, and what actions are available once the case reaches higher authority. In high-risk environments these pathways may involve multidisciplinary review groups including technical experts, legal advisors, and governance specialists.
Training requirements also appear prominently in mature oversight frameworks. The individuals responsible for reviewing AI outputs must understand both the operational domain and the behaviour of the AI system itself. Training programs often include modules covering model capabilities, limitations, common error patterns, and cognitive biases associated with automated decision support. These programs ensure that reviewers are equipped to challenge outputs when necessary rather than relying uncritically on automated recommendations.
The final element of the protocol concerns monitoring and auditing. Oversight activities generate valuable information about system performance and governance effectiveness. Logging mechanisms record every review decision, override action, and escalation event. Periodic audits then analyze these records to determine whether oversight processes are functioning as intended. Patterns discovered during these audits often lead to improvements in both the AI system and the governance framework surrounding it.
Organizations that implement such protocols discover that oversight becomes easier to sustain over time. Reviewers operate within a clear structure rather than relying on ad hoc judgement. Governance teams gain visibility into oversight performance, and leadership receives measurable evidence that human supervision remains effective. In this sense, the oversight protocol becomes a bridge between technical system design and institutional accountability.
Common Pitfalls in Human Oversight and How They Appear in Practice
Designing an oversight framework is not the same as ensuring that it functions effectively. Many organizations implement oversight procedures that appear robust on paper but gradually weaken during daily operation. These weaknesses rarely originate from a single technical flaw. More often they emerge from subtle interactions between system design, organizational incentives, and human behaviour. Understanding these patterns is essential because oversight failures tend to develop quietly before they become visible through incidents or regulatory scrutiny.
One of the most frequently discussed challenges is automation bias. This phenomenon occurs when human reviewers place excessive trust in automated outputs, even when contradictory information is available. Research in human–machine interaction has shown that people often interpret algorithmic recommendations as signals of authority. When a system appears confident, reviewers may hesitate to challenge its conclusions. Over time, this tendency can transform human oversight into a procedural step rather than an independent evaluation. Reviewers approve results quickly because the system appears reliable, and the oversight layer gradually loses its corrective function.
Automation bias becomes particularly pronounced in high-volume environments where reviewers face time pressure. If performance metrics reward speed or throughput, reviewers may feel compelled to process cases rapidly. In such environments the presence of human oversight may create a sense of reassurance without actually improving decision quality. The system appears supervised, yet the human role has little practical influence on outcomes.
Another oversight challenge arises when the reviewer lacks sufficient contextual information. AI outputs are rarely meaningful in isolation. They require interpretation within the broader context of the decision environment. If reviewers are presented with a prediction but cannot see the factors influencing that prediction, they are forced to rely on intuition rather than informed judgment. Effective oversight interfaces therefore provide contextual signals that help reviewers understand the reasoning or uncertainty behind the model’s output.
A related issue concerns organizational authority. Oversight frameworks sometimes assign review responsibilities to individuals who do not possess the authority to intervene when problems appear. A reviewer who cannot pause the system, request additional analysis, or escalate concerns effectively becomes a passive observer. In such situations the organization may claim that human oversight exists, yet the oversight process cannot meaningfully alter system behaviour.
Some governance researchers describe this situation as the “human lost in the queue” problem. The human reviewer appears within the decision workflow but lacks the tools, authority, or time needed to influence outcomes. Decisions move through the queue rapidly, reviewers process them under pressure, and the system continues operating even when concerns arise. Over time this structure erodes confidence in the oversight process itself.
Scalability also presents practical challenges. Certain AI systems generate outputs at volumes that make constant human review unrealistic. When organizations attempt to maintain full manual oversight under these conditions, the result often becomes reviewer fatigue. Fatigue increases the probability of oversight errors and reduces the likelihood that reviewers will detect subtle anomalies in system behaviour. In such contexts, hybrid oversight models that combine automated monitoring with targeted human intervention often prove more sustainable.
Another difficulty involves architectural separation between oversight processes and the systems they supervise. If oversight tools operate independently from the AI system, information may not flow efficiently between them. Reviewers might detect anomalies but lack the ability to trace the origin of the issue or understand how the system produced a particular output. Integrating oversight tools directly into system interfaces can significantly reduce this problem by allowing reviewers to access relevant data in real time.
Regulatory developments are also shaping how organizations approach these pitfalls. As regulatory frameworks such as the EU AI Act move toward enforcement, oversight claims are likely to face closer scrutiny. Authorities are increasingly interested not only in whether oversight procedures exist but in whether those procedures function effectively in practice. Documentation alone will not be sufficient. Organizations will need evidence demonstrating that reviewers can detect anomalies, intervene when necessary, and influence system behaviour.
A practical response to these challenges involves designing oversight frameworks that anticipate human limitations rather than ignoring them. This includes providing training that addresses automation bias, structuring review workloads to prevent fatigue, and designing interfaces that highlight uncertainty or unusual system behaviour. It also involves creating governance structures that encourage reviewers to question automated outputs without fear of organizational repercussions.
Effective oversight frameworks therefore operate on two levels simultaneously. At the technical level they provide tools that help reviewers understand system outputs. At the organizational level they create conditions in which human judgment is valued and supported. When these two levels align, oversight becomes more than a procedural requirement. It becomes an active mechanism for maintaining accountability within complex AI systems.
Human Oversight in Practice: Case Observations Across High-Risk Domains
Human oversight frameworks tend to reveal their strengths and weaknesses only after systems begin operating in real environments. Governance teams frequently discover that theoretical models of oversight behave differently once exposed to operational complexity. Workflows become busier, edge cases appear more frequently than expected, and the pressures of daily decision-making introduce practical constraints that were not visible during the design phase. Examining how oversight functions in different sectors provides insight into what makes oversight resilient rather than symbolic.
Healthcare environments illustrate this clearly. Clinical decision-support systems often assist physicians by highlighting potential diagnoses, suggesting treatment options, or prioritizing cases for review. In these environments human-in-the-loop oversight is not optional; medical professionals must remain responsible for interpreting the system’s output before making decisions affecting patient care. Effective oversight frameworks in healthcare therefore emphasize interpretability and professional judgment. Systems typically present evidence alongside predictions, allowing clinicians to understand the basis for the recommendation. Oversight occurs not merely through confirmation but through active interpretation of both the data and the model’s reasoning.
Financial services offer another perspective. Credit risk models, fraud detection tools, and transaction monitoring systems generate enormous volumes of automated signals. Full manual review of every decision would be impossible. As a result, many institutions rely on hybrid oversight models combining automated monitoring with human-on-the-loop supervision. Analysts review flagged transactions, investigate anomalies, and intervene when automated systems exceed predefined thresholds. In this environment oversight depends heavily on alert design, threshold calibration, and escalation procedures. When these mechanisms function effectively, human supervisors can focus on the most consequential decisions rather than reviewing routine outputs.
Public-sector decision systems present a different set of challenges. Governments increasingly rely on AI systems to support administrative decisions such as benefit eligibility assessments, tax compliance reviews, and resource allocation. These systems often operate within complex legal and social environments where errors can have significant consequences for individuals. Oversight frameworks in this context must balance efficiency with procedural fairness. Human reviewers must be able to challenge automated outputs, request additional information, and ensure that decisions remain consistent with legal standards. Transparency also becomes particularly important because public institutions must explain how automated tools influence administrative outcomes.
Industrial and manufacturing environments demonstrate another variation of oversight design. In automated production systems, AI models may detect anomalies in machinery performance, forecast maintenance needs, or optimize supply chains. Human oversight here focuses less on individual decisions and more on system behaviour over time. Engineers monitor system dashboards, investigate irregular patterns, and intervene when predictive models signal unusual operational conditions. In such environments human-on-the-loop supervision functions as an early warning system rather than a direct decision checkpoint.
Across these sectors a consistent pattern emerges. Oversight frameworks that succeed over time share several characteristics. First, they embed human judgment in places where intervention remains feasible. Second, they equip reviewers with interfaces that make system behaviour understandable. Third, they create organizational structures that support escalation rather than discouraging it. And finally, they treat oversight as an evolving process that improves through experience rather than a static control defined once during system deployment.
Measuring Oversight Effectiveness
One of the most overlooked aspects of human oversight frameworks is measurement. Organizations frequently assume that oversight exists simply because reviewers are present within the workflow. In reality, oversight effectiveness must be evaluated through observable indicators. Without measurement, governance teams cannot determine whether the oversight process is functioning as intended or merely creating the appearance of control.
Several metrics have emerged as useful indicators of oversight performance. One commonly used measure is the intervention rate. This metric records how often human reviewers override or modify automated outputs. Extremely low intervention rates may suggest that reviewers rarely challenge the system, raising questions about whether oversight is meaningful. Conversely, extremely high intervention rates may indicate weaknesses in the model itself or insufficient training data.
Another valuable metric involves response latency. When anomalies occur, organizations must assess how quickly human supervisors detect and respond to the issue. Delays in intervention can allow errors to propagate across large numbers of decisions before corrective action occurs. Monitoring response times helps governance teams evaluate whether oversight processes operate quickly enough to prevent harm.
Audit compliance indicators provide another dimension of oversight measurement. These indicators examine whether review decisions are properly documented and whether escalation procedures are followed when necessary. In regulatory environments documentation quality can become as important as the oversight action itself because it demonstrates that governance controls operate consistently.
Some organizations also track reviewer confidence and disagreement patterns. When reviewers consistently agree with automated outputs without discussion, it may indicate overreliance on the system. Conversely, frequent disagreement may reveal areas where the model requires refinement. Both patterns provide insight into how human and machine decision-making interact within the oversight framework.
These metrics do not replace qualitative evaluation, but they offer valuable signals that help governance teams monitor oversight health over time. By combining quantitative indicators with periodic qualitative reviews, organizations can maintain visibility into how human oversight functions across complex AI deployments.
The broader lesson from these case observations is that human oversight should not be treated as a static safeguard implemented once during deployment. It is an adaptive capability that evolves as systems change, operational environments shift, and organizations gain deeper understanding of how humans and algorithms interact in practice.
The Future of Human Oversight in AI Systems
The conversation around human oversight is evolving rapidly as AI systems become more capable and more deeply embedded in institutional decision-making. Early debates focused on whether humans should remain involved in automated processes at all. That question has largely been settled. The current challenge is determining how oversight can remain meaningful as AI systems scale in complexity and operational scope.
One emerging development is the increasing use of multi-AI workflows, where several automated systems interact with each other within a single operational pipeline. In such environments oversight cannot focus on a single model in isolation. Human supervisors must understand how outputs from one system influence decisions made by another. Oversight frameworks therefore begin to resemble broader system governance architectures rather than simple decision checkpoints.
Another development concerns the rise of agentic AI systems capable of performing sequences of actions with limited human intervention. These systems can plan, execute tasks, and adapt their behaviour in response to environmental feedback. While they offer substantial efficiency benefits, they also raise new governance challenges. Oversight mechanisms must now account for chains of decisions rather than isolated outputs. Organizations may need layered oversight models combining human-on-the-loop monitoring with predefined intervention triggers that allow humans to halt or redirect system activity.
Technological tools supporting oversight are also becoming more sophisticated. Explainability platforms, monitoring dashboards, and governance software increasingly allow organizations to visualize system behaviour in real time. These tools help reviewers identify unusual patterns, trace the origin of specific outputs, and document oversight decisions in ways that were difficult only a few years ago. As these tools mature, oversight frameworks will likely become more measurable and more transparent.
Regulatory expectations are evolving in parallel. The EU AI Act places explicit emphasis on human oversight for high-risk systems, but it is unlikely to remain the only framework addressing this issue. Governments around the world are examining similar governance mechanisms, and international organizations continue to develop guidelines emphasizing meaningful human control over automated decision systems. Organizations that invest early in well-designed oversight frameworks will therefore be better positioned to adapt to future regulatory developments.
The most significant shift, however, may be conceptual rather than technical. Human oversight is increasingly viewed not as a constraint on AI capability but as an enabling mechanism that allows organizations to deploy advanced systems responsibly. By maintaining human judgment within critical decision processes, organizations can expand the use of automation while preserving accountability and public trust.
Integrating Oversight into a Broader AI Governance Program
Human oversight does not operate in isolation. It interacts with several other components of AI governance, including risk management, data governance, system monitoring, and incident response procedures. When these elements function together, oversight becomes part of a comprehensive governance ecosystem rather than a single procedural step.
For example, oversight decisions often generate valuable information that feeds directly into monitoring and improvement processes. If reviewers frequently override particular outputs, those overrides may signal weaknesses in training data or model assumptions. Governance teams can analyze this information to refine the system or adjust oversight procedures accordingly. In this way oversight contributes not only to risk mitigation but also to continuous improvement.
Oversight frameworks also intersect with post-deployment monitoring programs. Monitoring systems track system behaviour over time, identifying trends such as performance drift or unusual activity patterns. When these monitoring signals indicate potential issues, human reviewers often become responsible for investigating the situation and determining whether corrective action is required. This relationship between monitoring and oversight reinforces the importance of viewing governance as an integrated system rather than a set of isolated controls.
Another important connection involves incident response. When an AI system produces outcomes that may harm individuals or violate regulatory obligations, human supervisors must be able to trigger incident response procedures quickly. Oversight frameworks therefore define how potential incidents are identified, documented, and escalated to the appropriate governance bodies. Clear escalation pathways ensure that concerns raised by reviewers lead to timely investigation and corrective action.
Organizations that successfully integrate oversight into broader governance programs often treat it as a shared institutional responsibility. Technical teams design systems that support oversight, governance teams define policies and procedures, and operational staff carry out the daily oversight activities. Collaboration between these groups ensures that oversight remains both technically feasible and organizationally supported.
Conclusion
Human oversight remains one of the most important safeguards in modern AI governance. As automated systems become more capable, the role of human judgment becomes more—not less—important. Oversight frameworks ensure that organizations retain the ability to question, interpret, and intervene in automated decision processes when risks arise.
Building effective oversight frameworks requires more than assigning a reviewer to approve automated outputs. It involves designing systems that support interpretability, defining clear intervention points, training reviewers to recognize system limitations, and establishing governance structures that encourage responsible escalation. When these elements come together, oversight becomes a functioning control rather than a symbolic gesture.
The regulatory landscape increasingly reflects this understanding. Frameworks such as the EU AI Act emphasize that high-risk AI systems must remain subject to meaningful human supervision. Organizations that approach oversight as a serious operational capability will therefore not only meet regulatory expectations but also strengthen the reliability and trustworthiness of their AI deployments.
Ultimately, responsible AI governance depends on preserving the relationship between technological capability and human judgment. AI systems may analyze data at extraordinary scale and speed, but accountability remains a human responsibility. Effective oversight frameworks ensure that this responsibility remains visible, structured, and enforceable—even as technology continues to evolve beyond the algorithm itself.
Human Oversight Protocol Template
Human oversight is a core requirement in modern AI governance frameworks.
For organizations designing oversight mechanisms around AI systems, a
structured protocol is essential for documenting roles, intervention
points, escalation procedures, and governance accountability.
The template below provides a practical framework for implementing
human oversight procedures within AI governance programs. It is designed
for governance teams, compliance officers, and organizations responsible
for supervising AI-enabled decision systems.
Human Oversight Protocol Template – AI Governance Desk
References
- European Parliament and Council of the European Union.
EU Artificial Intelligence Act – Article 14: Human Oversight
.
Accessed 2026.
↩ - European Union.
Regulation (EU) 2024/1689 of the European Parliament and of the Council on Artificial Intelligence
.
Official Journal of the European Union.
↩ - National Institute of Standards and Technology (NIST).
AI Risk Management Framework (AI RMF)
.
U.S. Department of Commerce.
↩ - Organisation for Economic Co-operation and Development (OECD).
OECD Principles on Artificial Intelligence
.
OECD Digital Policy Framework.
↩ - IBM Research.
What is Human-in-the-Loop AI?
.
IBM Think.
↩ - Center for Democracy & Technology.
Humans in the Loop: Governance Risks and Oversight in Automated Decision Systems
.
CDT Civic Technology Report, 2025.
↩
Frequently Asked Questions About Human-in-the-Loop Oversight Frameworks (FAQ)
What is human-in-the-loop oversight in AI governance?
Human-in-the-loop oversight refers to governance mechanisms where human judgment remains actively involved in AI-assisted decision processes. Instead of allowing automated outputs to trigger actions independently, designated reviewers evaluate outputs, confirm decisions, or intervene when anomalies appear. Within regulatory frameworks such as Article 14 of the EU AI Act, this oversight must be designed so humans can understand system behaviour, detect risks, and intervene effectively when necessary.
How does human-in-the-loop differ from human-on-the-loop oversight?
Human-in-the-loop oversight places human reviewers directly within the decision process, meaning certain outputs must be reviewed or approved before actions occur. Human-on-the-loop oversight operates at a supervisory level, where automated systems function continuously but human supervisors monitor behaviour and intervene when risk thresholds or anomalies are detected. Many high-risk AI systems combine both approaches to balance operational efficiency with human accountability.
Does the EU AI Act require human oversight for high-risk AI systems?
Yes. Article 14 of the EU AI Act requires providers of high-risk AI systems to design systems so they can be effectively overseen by natural persons during operation. Oversight mechanisms must allow human supervisors to understand system capabilities and limitations, detect abnormal behaviour, and intervene or stop the system when necessary to prevent risks to health, safety, or fundamental rights.
What are the most common failures in human oversight frameworks?
Oversight frameworks often fail due to automation bias, insufficient reviewer training, lack of authority to intervene, or poorly designed system interfaces that hide critical signals. Another frequent issue is the “rubber-stamping” phenomenon, where human reviewers approve outputs without meaningful evaluation due to workload pressure or overreliance on automated systems.
How can organizations measure whether human oversight is working?
Oversight effectiveness can be evaluated through indicators such as reviewer intervention rates, escalation frequency, anomaly detection response times, override justifications, and audit documentation quality. These metrics help organizations determine whether human oversight is actively influencing decisions or merely existing as a procedural formality.
Covering responsible AI, governance frameworks, policy, ethics, and global regulations shaping the future of artificial intelligence.
